
这是一个创建于 73 天前的主题,其中的信息可能已经有所发展或是发生改变。
今天刚把 IntelliJ IDEA 更新到了 2025.1 版本,主要是想看看这次 AI Assistant 有什么新东西。之前看到消息说功能有更新,而且似乎可以免费试用,就动手试了试,顺便把过程和一些发现记录下来,给可能需要的朋友一个参考。
一、启用 AI Assistant 试用
之前的版本 AI Assistant 对国内用户不太友好,这次更新后,我发现通过调整区域设置,可以重新弹出 AI Assistant 的登录和试用选项。
具体步骤是这样的:
-
确认 IDEA 版本: 确保是 2025.1 或更新版本。
-
修改地区设置:
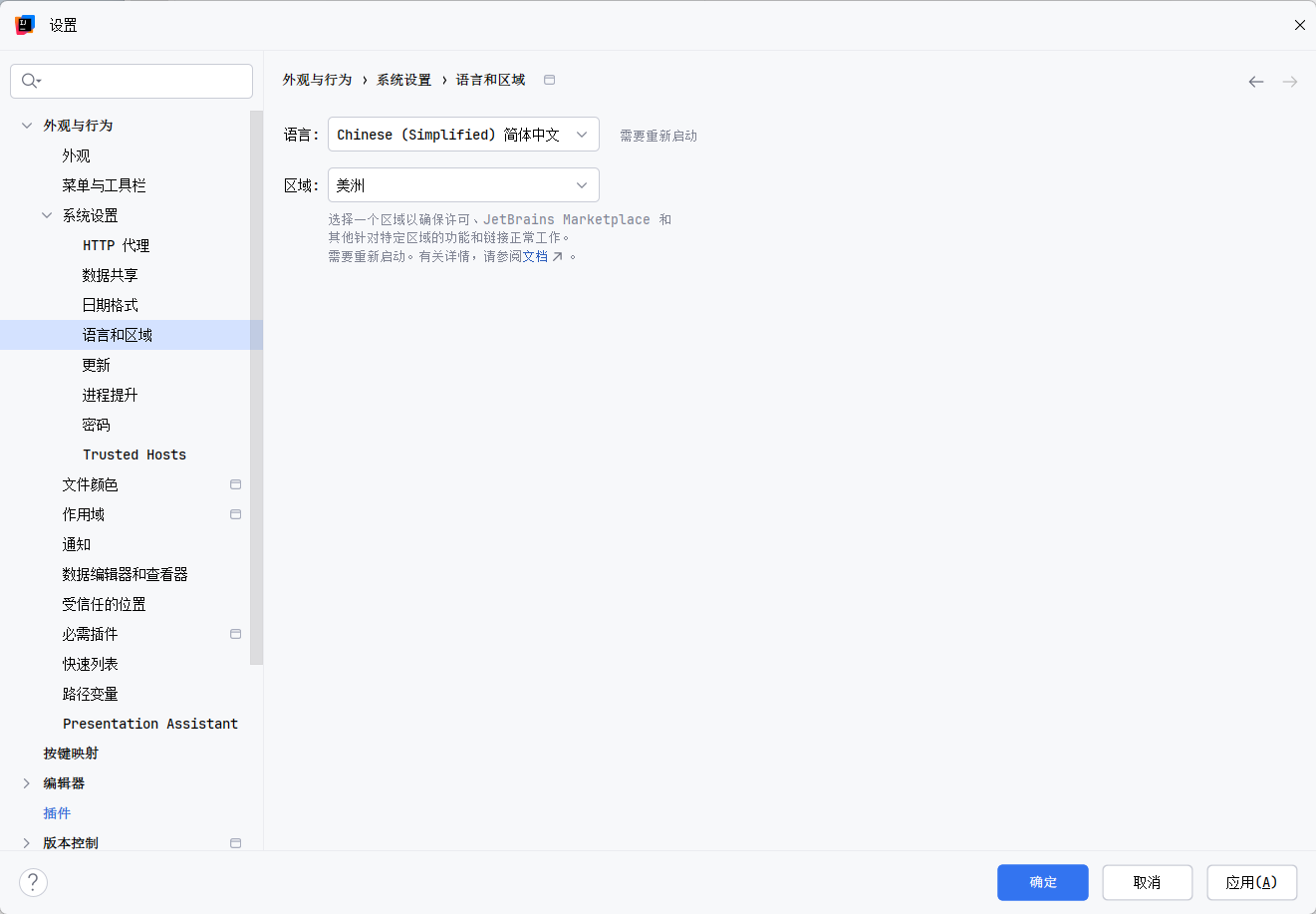
-
重启 IDEA: 必须完全关闭 IDEA 再重新打开,让配置生效。
-
检查 AI Assistant 插件:
- 去
Settings/Preferences->Plugins->Installed确认AI Assistant,Junie插件是启用状态。如果没有,去Marketplace搜索安装一下。
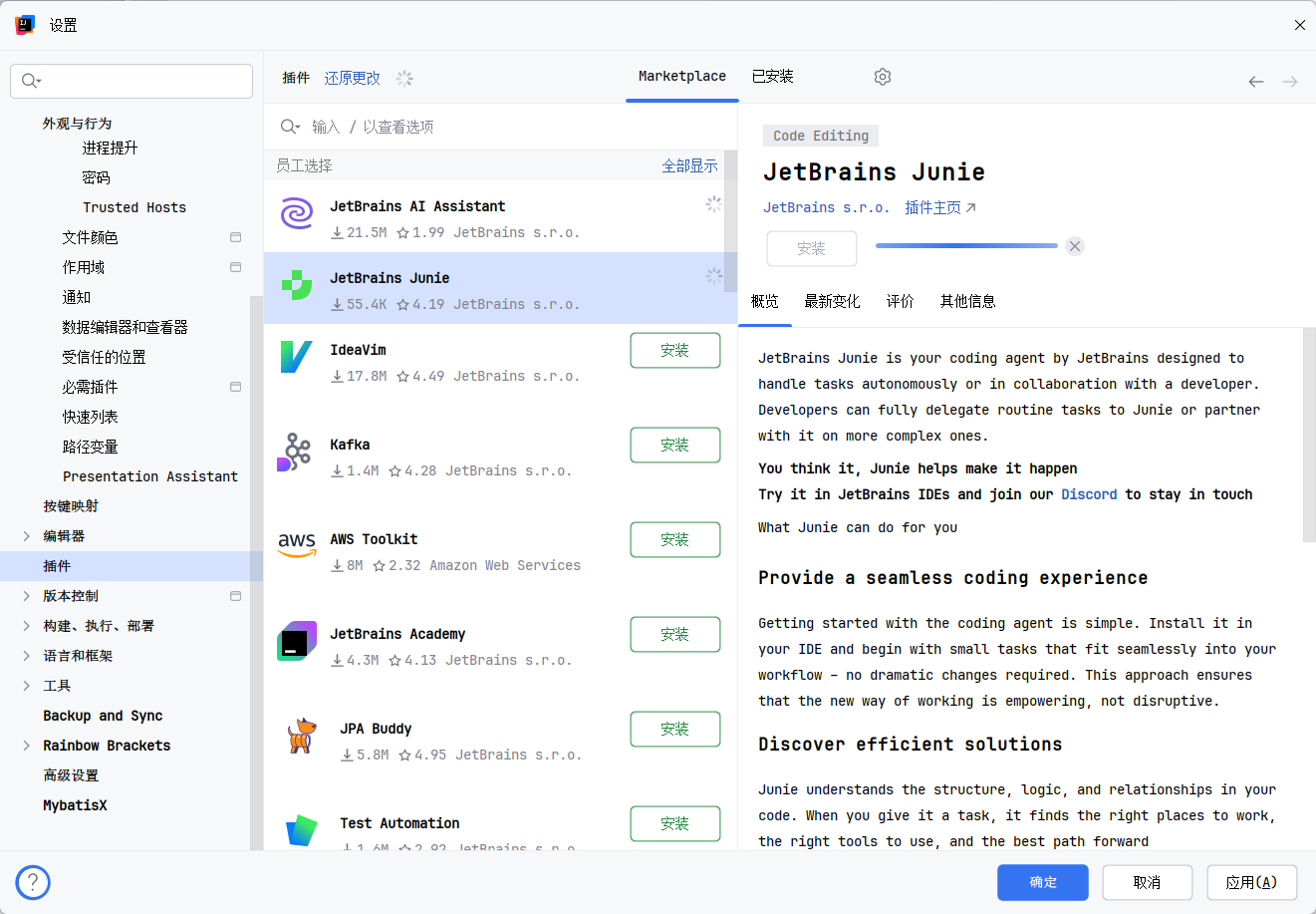
- 去
-
登录并开始试用:
- 重启后,IDE 右侧应该会出现 AI Assistant 的工具窗口。点击登录你的 JetBrains 账号。
- 登录成功后,应该会看到一个 "Start Trial" 或类似的按钮,点击它就可以开始试用了。

注意: 这个方法本质上是开启了 JetBrains 提供的试用期。试用期有多长、结束后政策如何,目前还不确定。这更像是一个基于区域的试用策略,不保证长期有效。
二、新东西:Agent AI
这次更新除了常规的 AI 功能(代码补全、解释、生成 Commit Message 等),比较有意思的是推出了一个叫 "Agent AI" 的东西。
看介绍和初步试用,它似乎不只是建议,而是可以直接参与到跨文件、更复杂的代码修改任务中。比如你可以让它分析某个方法的调用链,或者尝试进行一些重构。
这个功能看起来潜力挺大,可以直接在 IDE 里处理一些稍微繁琐的任务。具体效果怎么样,还需要在实际项目中多用用看。


三、连接本地模型(可选)
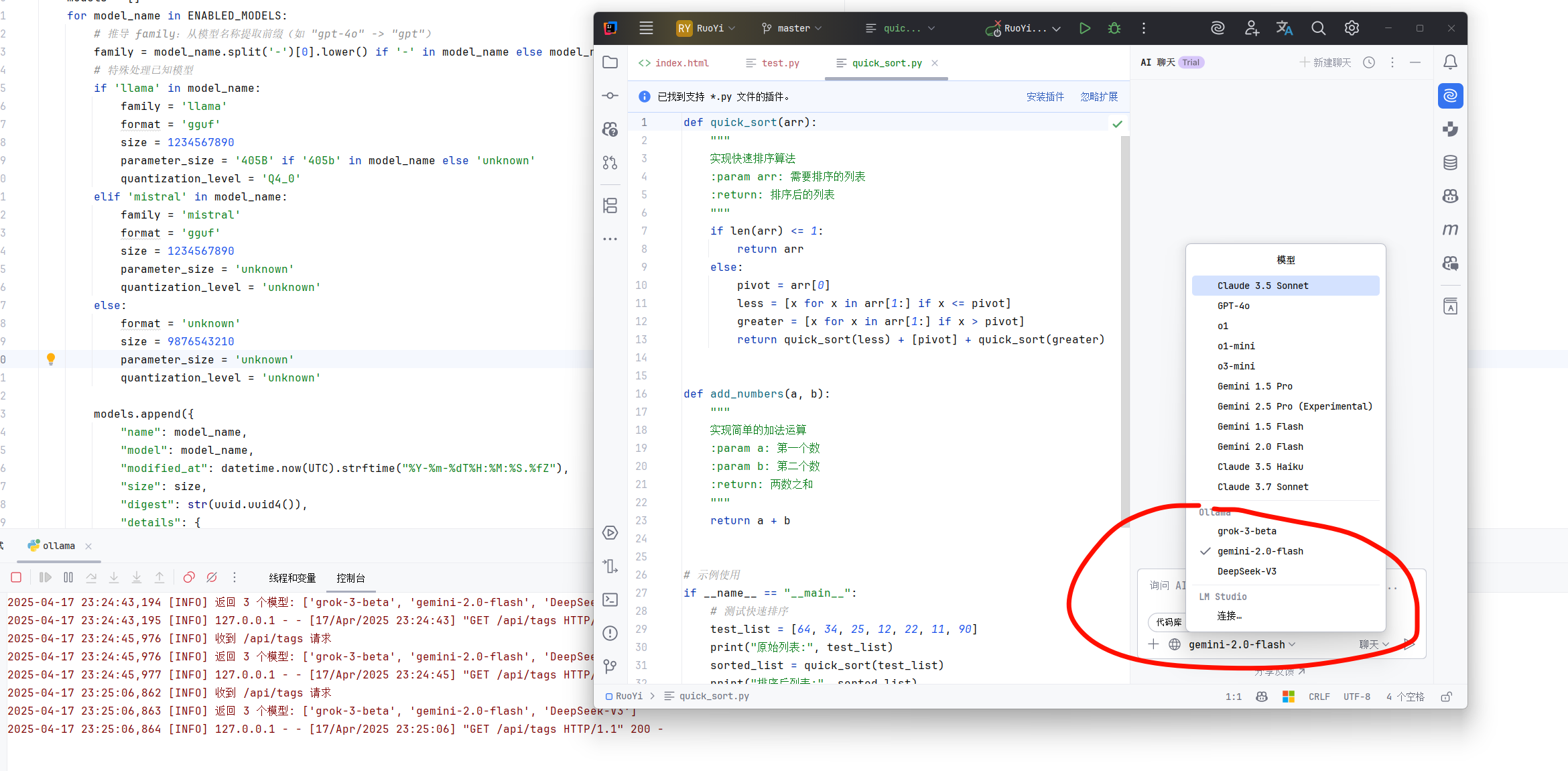
对于注重隐私或者想用特定模型的开发者,AI Assistant 现在也支持连接本地运行的大语言模型了。
-
本地运行模型: 如果你本地用 Ollama 或其他兼容 OpenAI API 格式的服务跑了模型(比如 Llama 3, Qwen, Gemma 等),确保服务在运行。
-
配置 IDEA:
- 打开
Settings/Preferences->Tools->AI Assistant->LLM Service。 - 选择
Custom或Local(具体选项名称可能微调),然后填入你本地服务的地址,比如 Ollama 默认的http://localhost:11434。

- 打开
本地跑不动模型怎么办?
我看有人整理了一些提供免费在线 Ollama 服务的列表(比如这个:https://idea.wangwangit.com/zh),你可以找一个试试看,配置方法和本地一样,填入对应的服务地址就行。不过用第三方服务,数据隐私方面就需要自己衡量了。
ollama 模型太辣鸡?
那就让我抛出重磅级武器吧,直接接入第三方 API, 修改API_URL,API_KEY为自己的配置,在ENABLED_MODELS中添加合适的模型,然后在本地或者服务器启动这份代码! 就可以集成各种在线 AI 模型使用啦!
from flask import Flask, request, jsonify
import requests
import time
import uuid
import logging
import json
from typing import Dict, Any
from datetime import datetime, UTC
# 配置日志(更改为中文)
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
handlers=[logging.StreamHandler()]
)
logger = logging.getLogger(__name__)
app = Flask(__name__)
# 启用模型配置:直接定义启用的模型名称
# 用户可添加/删除模型名称,动态生成元数据
ENABLED_MODELS = {
"gemini-2.0-flash",
"grok-3-beta",
"DeepSeek-V3"
}
# API 配置
API_URL = "https://xxxx/v1/chat/completions"
# 请替换为你的 API 密钥(请勿公开分享)
API_KEY = "xxxxx"
# 模拟 Ollama 聊天响应数据库
OLLAMA_MOCK_RESPONSES = {
"What is the capital of France?": "The capital of France is Paris.",
"Tell me about AI.": "AI is the simulation of human intelligence in machines, enabling tasks like reasoning and learning.",
"Hello": "Hi! How can I assist you today?"
}
@app.route("/", methods=["GET"])
def root_endpoint():
"""模拟 Ollama 根路径,返回 'Ollama is running'"""
logger.info("收到根路径请求")
return "Ollama is running", 200
@app.route("/api/tags", methods=["GET"])
def tags_endpoint():
"""模拟 Ollama 的 /api/tags 端点,动态生成启用模型列表"""
logger.info("收到 /api/tags 请求")
models = []
for model_name in ENABLED_MODELS:
# 推导 family:从模型名称提取前缀(如 "gpt-4o" -> "gpt")
family = model_name.split('-')[0].lower() if '-' in model_name else model_name.lower()
# 特殊处理已知模型
if 'llama' in model_name:
family = 'llama'
format = 'gguf'
size = 1234567890
parameter_size = '405B' if '405b' in model_name else 'unknown'
quantization_level = 'Q4_0'
elif 'mistral' in model_name:
family = 'mistral'
format = 'gguf'
size = 1234567890
parameter_size = 'unknown'
quantization_level = 'unknown'
else:
format = 'unknown'
size = 9876543210
parameter_size = 'unknown'
quantization_level = 'unknown'
models.append({
"name": model_name,
"model": model_name,
"modified_at": datetime.now(UTC).strftime("%Y-%m-%dT%H:%M:%S.%fZ"),
"size": size,
"digest": str(uuid.uuid4()),
"details": {
"parent_model": "",
"format": format,
"family": family,
"families": [family],
"parameter_size": parameter_size,
"quantization_level": quantization_level
}
})
logger.info(f"返回 {len(models)} 个模型: {[m['name'] for m in models]}")
return jsonify({"models": models}), 200
def generate_ollama_mock_response(prompt: str, model: str) -> Dict[str, Any]:
"""生成模拟的 Ollama 聊天响应,符合 /api/chat 格式"""
response_content = OLLAMA_MOCK_RESPONSES.get(
prompt, f"Echo: {prompt} (这是来自模拟 Ollama 服务器的响应。)"
)
return {
"model": model,
"created_at": datetime.now(UTC).strftime("%Y-%m-%dT%H:%M:%SZ"),
"message": {
"role": "assistant",
"content": response_content
},
"done": True,
"total_duration": 123456789,
"load_duration": 1234567,
"prompt_eval_count": 10,
"prompt_eval_duration": 2345678,
"eval_count": 20,
"eval_duration": 3456789
}
def convert_api_to_ollama_response(api_response: Dict[str, Any], model: str) -> Dict[str, Any]:
"""将 API 的 OpenAI 格式响应转换为 Ollama 格式"""
try:
content = api_response["choices"][0]["message"]["content"]
total_duration = api_response.get("usage", {}).get("total_tokens", 30) * 1000000
prompt_tokens = api_response.get("usage", {}).get("prompt_tokens", 10)
completion_tokens = api_response.get("usage", {}).get("completion_tokens", 20)
return {
"model": model,
"created_at": datetime.now(UTC).strftime("%Y-%m-%dT%H:%M:%SZ"),
"message": {
"role": "assistant",
"content": content
},
"done": True,
"total_duration": total_duration,
"load_duration": 1234567,
"prompt_eval_count": prompt_tokens,
"prompt_eval_duration": prompt_tokens * 100000,
"eval_count": completion_tokens,
"eval_duration": completion_tokens * 100000
}
except KeyError as e:
logger.error(f"转换 API 响应失败: 缺少键 {str(e)}")
return {"error": f"无效的 API 响应格式: 缺少键 {str(e)}"}
def print_request_params(data: Dict[str, Any], endpoint: str) -> None:
"""打印请求参数"""
model = data.get("model", "未指定")
temperature = data.get("temperature", "未指定")
stream = data.get("stream", False)
messages_info = []
for msg in data.get("messages", []):
role = msg.get("role", "未知")
content = msg.get("content", "")
content_preview = content[:50] + "..." if len(content) > 50 else content
messages_info.append(f"[{role}] {content_preview}")
params_str = {
"端点": endpoint,
"模型": model,
"温度": temperature,
"流式输出": stream,
"消息数量": len(data.get("messages", [])),
"消息预览": messages_info
}
logger.info(f"请求参数: {json.dumps(params_str, ensure_ascii=False, indent=2)}")
@app.route("/api/chat", methods=["POST"])
def ollama_chat_endpoint():
"""模拟 Ollama 的 /api/chat 端点,所有模型都能使用"""
try:
data = request.get_json()
if not data or "messages" not in data:
logger.error("无效请求: 缺少 'messages' 字段")
return jsonify({"error": "无效请求: 缺少 'messages' 字段"}), 400
messages = data.get("messages", [])
if not messages or not isinstance(messages, list):
logger.error("无效请求: 'messages' 必须是非空列表")
return jsonify({"error": "无效请求: 'messages' 必须是非空列表"}), 400
model = data.get("model", "llama3.2")
user_message = next(
(msg["content"] for msg in reversed(messages) if msg.get("role") == "user"),
""
)
if not user_message:
logger.error("未找到用户消息")
return jsonify({"error": "未找到用户消息"}), 400
# 打印请求参数
print_request_params(data, "/api/chat")
logger.info(f"处理 /api/chat 请求, 模型: {model}")
# 移除模型限制,所有模型都使用 API
api_request = {
"model": model,
"messages": messages,
"stream": False,
"temperature": data.get("temperature", 0.7)
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
try:
logger.info(f"转发请求到 API: {API_URL}")
response = requests.post(API_URL, json=api_request, headers=headers, timeout=30)
response.raise_for_status()
api_response = response.json()
ollama_response = convert_api_to_ollama_response(api_response, model)
logger.info(f"收到来自 API 的响应,模型: {model}")
return jsonify(ollama_response), 200
except requests.RequestException as e:
logger.error(f"API 请求失败: {str(e)}")
# 如果 API 请求失败,使用模拟响应作为备用
logger.info(f"使用模拟响应作为备用方案,模型: {model}")
response = generate_ollama_mock_response(user_message, model)
return jsonify(response), 200
except Exception as e:
logger.error(f"/api/chat 服务器错误: {str(e)}")
return jsonify({"error": f"服务器错误: {str(e)}"}), 500
@app.route("/v1/chat/completions", methods=["POST"])
def api_chat_endpoint():
"""转发到 API 的 /v1/chat/completions 端点,并转换为 Ollama 格式"""
try:
data = request.get_json()
if not data or "messages" not in data:
logger.error("无效请求: 缺少 'messages' 字段")
return jsonify({"error": "无效请求: 缺少 'messages' 字段"}), 400
messages = data.get("messages", [])
if not messages or not isinstance(messages, list):
logger.error("无效请求: 'messages' 必须是非空列表")
return jsonify({"error": "无效请求: 'messages' 必须是非空列表"}), 400
model = data.get("model", "grok-3")
user_message = next(
(msg["content"] for msg in reversed(messages) if msg.get("role") == "user"),
""
)
if not user_message:
logger.error("未找到用户消息")
return jsonify({"error": "未找到用户消息"}), 400
# 打印请求参数
print_request_params(data, "/v1/chat/completions")
logger.info(f"处理 /v1/chat/completions 请求, 模型: {model}")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
try:
logger.info(f"转发请求到 API: {API_URL}")
response = requests.post(API_URL, json=data, headers=headers, timeout=30)
response.raise_for_status()
api_response = response.json()
ollama_response = convert_api_to_ollama_response(api_response, model)
logger.info(f"收到来自 API 的响应,模型: {model}")
return jsonify(ollama_response), 200
except requests.RequestException as e:
logger.error(f"API 请求失败: {str(e)}")
return jsonify({"error": f"API 请求失败: {str(e)}"}), 500
except Exception as e:
logger.error(f"/v1/chat/completions 服务器错误: {str(e)}")
return jsonify({"error": f"服务器错误: {str(e)}"}), 500
def main():
"""启动模拟服务器"""
logger.info("正在启动模拟 Ollama 和 API 代理服务器,地址: http://localhost:11434")
app.run(host="0.0.0.0", port=11434, debug=False)
if __name__ == "__main__":
main()

总结
总的来说,IDEA 2025.1 的 AI 功能值得尝试一下,尤其是通过改区域设置就能方便地开启试用。Agent AI 是个新方向,看看后续发展如何。连接本地模型也给了大家更多选择。
我就先用到这儿,算是个快速上手记录。如果你也更新了,欢迎交流使用体验,特别是 Agent AI 的实战效果。
13 条回复 • 2025-05-06 18:39:45 +08:00
 |
1
PrettyJack 73 天前
选的亚太地区,开启试用还要填写付款信息
|
 |
2
AEnjoyable 73 天前 via Android
奇怪 为啥我国区的账号就能直接试用...
(正版账号 自己的号) |
 |
3
tsundoku 72 天前
@AEnjoyable 我才发现 JetBrains AI 已经包含在全家桶里面了
|
 |
4
abellis 72 天前
之前试用过 7 天不能再试用了。。。
|

 |
7
EastLord 72 天前 via iPhone
不是说一直免费吗
|
 |
8
lee88688 72 天前
我看他的博客上面好像也是写了基础功能全部可以免费使用的(至少 local model 要用把),但是我自己花钱买的升级到这个版本之后什么都用不了(我之前试用过 pro ,已经到期了)。
我觉得 jetbrain 太拉跨了,本来 ai 功能很难用,我之前买他就是图他 IDE 做的还可以,但是现在 vscode 上面 agent 和 AI 相关的插件都快把你的份额吃完了官方都还这么扭捏,升级之后说是免费用但我自己用自己的 api 的 chat 都不行。在 vscode 上面不管是 cline 还是 roo cline 哪个不好用,一堆免费自动补全的插件。 我买了三年他们家的 IDE ,目前已经续费 cursor 好几个月了,如果他们今年没有支持本地的 chat 和 agent 我已经不想续费了😂。 |
 |
10
JoeyLi9527 72 天前
复刻了 OP 的代码,哈哈哈
|
 |
11
luckybricks9711 72 天前
@lee88688 全家桶里现在已经带上 AI Pro 许可证了啊,本地用 Ollama + LMStudio 就是 op 的这个解决方案
|
|
12
lee88688 71 天前
@luckybricks9711 怪不得我不行,全开通才可以,我就买了一个。看来我还是不配用他们的 ai😂
|
 |
13
chiaoyuja 54 天前
webstorm 我改了 region 美国了,重启后还是提示 Unfortunately, Al Assistant is currently unavailable in
your location ,要开全局代理吗 |